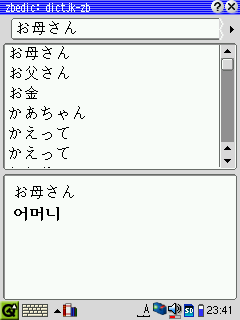
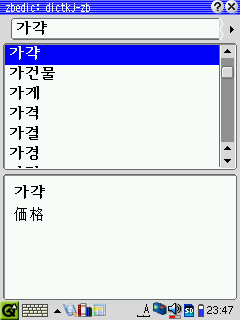
|
■ CEDICT → ZBEDic 変換: 自作 Perl Script(1) CEDICT は一行テキスト形式の辞書になっていますが、ZBEDicの辞書は一種の「PDICテキスト形式」(一行目に単語、二行目にその意味、といった形式)で、もう少し構造化された形になっています。辞書の書式についての解説ページがありましたので、それを翻訳(下記)しておきました。 また、CEDICT は GB(簡体字の中国国家標準コード)で書かれていますが、ZBEDic辞書は UTF-8 でエンコードされていなければなりません。ここでは、各種文字コードに対応したとても素晴らしいエディタである xyzzy を使用してGB から UTF-8 への変換等を行いました。 なお、Perl本体は ActivePerl のページから(Windows版、Linux版)ダウンロードして下さい。また、Perlスクリプトを書くに当たっては AOKさん 作の「Perlを始めよう」というソフトが一種の統合開発環境を提供していて、とても効率的に作業ができます。 「Perlを始めよう」のスクリーンショット 【変換の手順】 ◆ CEDICT → ZBEDic形式の中英辞書 1. cedictgb.zip をダウンロードして解凍する。 2. perlスクリプト conv-c2zb.pl を上記の辞書ファイルと同じディレクトリ と[zhong4])があった場合、最初の語句しか検索されてこないという指摘 があり、この点を修正したスクリプト conv-c2zb-v2.pl をアップしました。 今後はこちらを使って下さい。(2006.1) なお、この場合出力されるテキストは cedict-zb-v2.txt になります。 3. cedict-zb.txt というファイルが生成されるので、これを xyzzy
で読み込 4. cedict-zb-u8.txt を Zaurus に転送し、xerox
で圧縮する(辞書名は、 ※xerox
は、単に辞書を圧縮するだけではなく辞書インデックスも作っている ◆ CEDICT → ZBEDic形式の英中辞書 1. 先ず、CEDICT
から一行テキスト形式の英中辞書にコンバートした ECDICT 2. 次に、xyzzy
を使い、これを UFT-8 に変換(ecdict-u8-ol.txt)。 3. 更に、ZBEDic形式に変換(ecdict-zb.txt)。 4. Zaurus に転送し、xerox で圧縮。 ※ なお、本家 EDICTのページ(モナシュ大学日本語アーカイブ) には
EDICT の ■ KJ_dict → ZBEDic 変換: 自作 Perl Script(2)
【変換の手順】 ◆ KJ_dict → ZBEDic形式の日韓辞書 1. kj_dict.zip をダウンロードして解凍する。 2. perlスクリプト jk2ol.pl
を上記の辞書ファイルと同じディレクトリにコピ 3. 更に、cvn-jk2zb.pl を同じディレクトリに置いて実行(ZBEDic形式に変換)。 4. Zaurusに転送し、xerox で圧縮。 ◆ KJ_dict → ZBEDic形式の韓日辞書 1. 上記と同様、dictkj.yml → dictkj-ol.txt → dictkj-zb.txt
と変換し、 ※最近(2004.3.20頃)KJ_dict
の書式が変更になりました(v0.2.5→v0.3.1)。 ※KJ_dict 最新版(v0.13.2)への対応(05,8/12)。 ※KJ_dict 最新版(v0.16.4)への対応(06,1/3)。
■ bedic辞書の書式(英語原文及び日本語訳)
----------------- 【日本語訳】 bedic辞書のファイルはヘッダとエントリの二つの部分から成っている。辞書ファイルは、文字'\000'で終わる。 Ⅰ.ヘッダ部分 ヘッダは辞書の属性を示している。ヘッダの全てのデータはUTF-8でエンコードされている。ヘッダ終わりは、文字 \0 で画される。 1.属性 一つの属性定義は次の書式に従う: LFはラインフィード(\012)である。nameとvalueは、両方とも下記に定義されているような 0 と LF を含むことができる。 \0000 \0033 \0060 (ESC '0') ESCは 033 である。name は文字 '='(075)を含むことができない。 次は、当面定義されている属性である。 - id (必須) - max-entry-length (default 8192) - max-word-length (default 50) - index - compression-method (default none) - shcm-tree (圧縮方法が shcm なら必須) - search-ignore-chars (default '-.') - commentXX 他の全ての属性は無視される。 2.index 属性 index 属性があれば辞書検索のスピードが増進する。 index は対になった (word, offset) 集合を含む。
単語は(文字コードと search-ignore-chars で定義された文字を無視して)整列される。 offset
は、ファイルのエントリセクションの最初からの相対値。各々の対 (word, offset) は、文字 \000 で画され、 word と
offset は、文字 \012 で画される (両文字とも、全ての属性 value と同様、 \033 \0060 Ⅱ.エントリセクション エントリセクションは、辞書エントリの集合を含む。各エントリは可変長のサイズである。各エントリは、単語と意味の二つの部分からなる。ある単語は、他の単語と重複してはいけない。全てのエントリは(文字コードと search-ignore-chars で定義された文字を無視して)単語値によって整列させられる。 1. エントリセクションの書式 <entry0> '\0' <entry1> ... <entryN> '\0' 辞書の各エントリは、文字 \0 によって分離される。 2. 各エントリの書式 <word> '\012' <meaning> 単語と意味は、文字 \012 (LF) で分離される。 3. Meaning(意味)の書式 単語の意味(meaning)はフリーテキスト書式ではない。 それはいくつかのタグによって定義される構造をもっている。タグの書式は次の通りである。 '{' タグ名 '}' 開始タグ ある単語は一つあるいはもっと多くの意味(sence)をもつ。ある単語が、異なる品詞の異なる同音異義語か意味をもつ場合には、異なる意味(sence)として定義される。 各々の意味(sence)について、品詞と発音が定義される。 一つの意味(sence)には、一つまたはそれ以上の副意味(sub-sence)が定義される。副意味(sub-sence)タグの中には、単語の訳/定義が置かれる。そこにはまた、辞書の他の単語へのポインター 関連語(_see-also_ )タグ、 用例 (_example_) タグ、あるいは見出し語(_headword_)タグが含まれる。 タグ: 意味(sense) {s}
単語 test1 の意味 {s}{ps}n{/ps}{pr}test{/pr}{ss}sub-sense one{/ss}{ss}sub-sense
two{/ss}{/s} は、次のように表示される。 test1 n /test/ 1. sub-sense one ------------------------------- test1 v /test/ see also _hop_ III. SHCM 圧縮 bedic は simple Huffman code を元とした圧縮をサポートしている。この圧縮方法は Alexander Simakov <xander@online.ru>による shcodec program に基づいている。 速い検索を可能にするため、各単語と意味は分離して圧縮される。圧縮されたデータの中の '\0', '\n', '\033' は、属性値の中それと同様な方法でエンコードされる。 Version: 0.8
|